|
ILIAS
Release_4_0_x_branch Revision 61816
|
|
ILIAS
Release_4_0_x_branch Revision 61816
|
 Collaboration diagram for Sanitizer:
Collaboration diagram for Sanitizer:Static Public Member Functions | |
| static | validateTagAttributes ($attribs, $element) |
| Take an array of attribute names and values and normalize or discard illegal values for the given element type. | |
| static | checkCss ($value) |
| Pick apart some CSS and check it for forbidden or unsafe structures. | |
| static | fixTagAttributes ($text, $element) |
| Take a tag soup fragment listing an HTML element's attributes and normalize it to well-formed XML, discarding unwanted attributes. | |
| static | encodeAttribute ($text) |
| Encode an attribute value for HTML output. | |
| static | safeEncodeAttribute ($text) |
| Encode an attribute value for HTML tags, with extra armoring against further wiki processing. | |
| static | escapeId ($id) |
| Given a value escape it so that it can be used in an id attribute and return it, this does not validate the value however (see first link) | |
| static | escapeClass ($class) |
| Given a value, escape it so that it can be used as a CSS class and return it. | |
| static | decodeTagAttributes ($text) |
| Return an associative array of attribute names and values from a partial tag string. | |
| static | normalizeCharReferencesCallback ($matches) |
| static | normalizeEntity ($name) |
| If the named entity is defined in the HTML 4.0/XHTML 1.0 DTD, return the named entity reference as is. | |
| static | decCharReference ($codepoint) |
| static | hexCharReference ($codepoint) |
| static | decodeCharReferences ($text) |
| Decode any character references, numeric or named entities, in the text and return a UTF-8 string. | |
| static | decodeCharReferencesCallback ($matches) |
| static | decodeEntity ($name) |
| If the named entity is defined in the HTML 4.0/XHTML 1.0 DTD, return the UTF-8 encoding of that character. | |
| static | attributeWhitelist ($element) |
| Fetch the whitelist of acceptable attributes for a given element name. | |
| static | setupAttributeWhitelist () |
| static | stripAllTags ($text) |
| Take a fragment of (potentially invalid) HTML and return a version with any tags removed, encoded as plain text. | |
| static | hackDocType () |
| Hack up a private DOCTYPE with HTML's standard entity declarations. | |
| static | cleanUrl ($url, $hostname=true) |
Static Private Member Functions | |
| static | removeHTMLtags ($text, $processCallback=null, $args=array()) |
| Cleans up HTML, removes dangerous tags and attributes, and removes HTML comments. | |
| static | removeHTMLcomments ($text) |
| Remove '', and everything between. | |
| static | armorLinksCallback ($matches) |
| Regex replace callback for armoring links against further processing. | |
| static | getTagAttributeCallback ($set) |
| Pick the appropriate attribute value from a match set from the MW_ATTRIBS_REGEX matches. | |
| static | normalizeAttributeValue ($text) |
| Normalize whitespace and character references in an XML source- encoded text for an attribute value. | |
| static | normalizeWhitespace ($text) |
| static | normalizeCharReferences ($text) |
| Ensure that any entities and character references are legal for XML and XHTML specifically. | |
| static | validateCodepoint ($codepoint) |
| Returns true if a given Unicode codepoint is a valid character in XML. | |
| static | decodeChar ($codepoint) |
| Return UTF-8 string for a codepoint if that is a valid character reference, otherwise U+FFFD REPLACEMENT CHARACTER. | |
Definition at line 330 of file Sanitizer.php.
|
staticprivate |
Regex replace callback for armoring links against further processing.
| array | $matches |
Definition at line 772 of file Sanitizer.php.
|
static |
Fetch the whitelist of acceptable attributes for a given element name.
| string | $element |
Definition at line 1041 of file Sanitizer.php.
|
static |
Pick apart some CSS and check it for forbidden or unsafe structures.
Returns a sanitized string, or false if it was just too evil.
Currently URL references, 'expression', 'tps' are forbidden.
| string | $value |
Definition at line 611 of file Sanitizer.php.
|
static |
Definition at line 1232 of file Sanitizer.php.
|
static |
Definition at line 932 of file Sanitizer.php.
|
staticprivate |
Return UTF-8 string for a codepoint if that is a valid character reference, otherwise U+FFFD REPLACEMENT CHARACTER.
| int | $codepoint |
Definition at line 1005 of file Sanitizer.php.
|
static |
Decode any character references, numeric or named entities, in the text and return a UTF-8 string.
| string | $text |
Definition at line 973 of file Sanitizer.php.
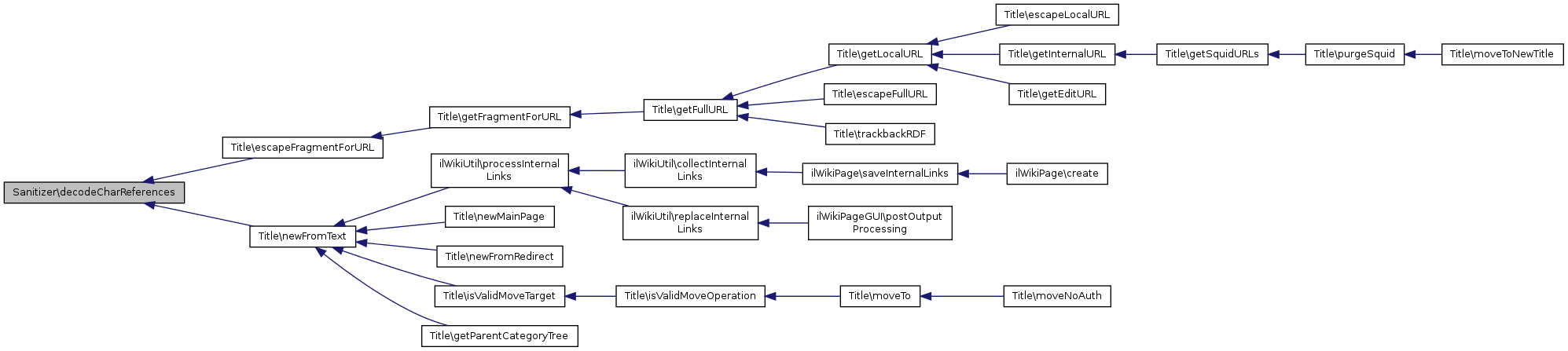
Referenced by Title\escapeFragmentForURL(), and Title\newFromText().
Here is the caller graph for this function:
|
static |
| string | $matches |
Definition at line 984 of file Sanitizer.php.
|
static |
If the named entity is defined in the HTML 4.0/XHTML 1.0 DTD, return the UTF-8 encoding of that character.
Otherwise, returns pseudo-entity source (eg )
| string | $name |
Definition at line 1021 of file Sanitizer.php.
|
static |
Return an associative array of attribute names and values from a partial tag string.
Attribute names are forces to lowercase, character references are decoded to UTF-8 text.
| string |
Definition at line 784 of file Sanitizer.php.
|
static |
Encode an attribute value for HTML output.
| $text |
Definition at line 674 of file Sanitizer.php.
|
static |
Given a value, escape it so that it can be used as a CSS class and return it.
| string | $class |
Definition at line 758 of file Sanitizer.php.
|
static |
Given a value escape it so that it can be used in an id attribute and return it, this does not validate the value however (see first link)
| string | $id |
Definition at line 736 of file Sanitizer.php.
|
static |
Take a tag soup fragment listing an HTML element's attributes and normalize it to well-formed XML, discarding unwanted attributes.
Output is safe for further wikitext processing, with escaping of values that could trigger problems.
| string | $text | |
| string | $element |
Definition at line 651 of file Sanitizer.php.
|
staticprivate |
Pick the appropriate attribute value from a match set from the MW_ATTRIBS_REGEX matches.
| array | $set |
Definition at line 822 of file Sanitizer.php.
|
static |
Hack up a private DOCTYPE with HTML's standard entity declarations.
PHP 4 seemed to know these if you gave it an HTML doctype, but PHP 5.1 doesn't.
Use for passing XHTML fragments to PHP's XML parsing functions
Definition at line 1222 of file Sanitizer.php.
|
static |
Definition at line 941 of file Sanitizer.php.
|
staticprivate |
Normalize whitespace and character references in an XML source- encoded text for an attribute value.
See http://www.w3.org/TR/REC-xml/#AVNormalize for background, but note that we're not returning the value, but are returning XML source fragments that will be slapped into output.
| string | $text |
Definition at line 856 of file Sanitizer.php.
|
staticprivate |
Ensure that any entities and character references are legal for XML and XHTML specifically.
Any stray bits will be &-escaped to result in a valid text fragment.
a. any named char refs must be known in XHTML b. any numeric char refs must be legal chars, not invalid or forbidden c. use &#x, not &#X d. fix or reject non-valid attributes
| string | $text |
Definition at line 883 of file Sanitizer.php.
|
static |
| string | $matches |
Definition at line 893 of file Sanitizer.php.
|
static |
If the named entity is defined in the HTML 4.0/XHTML 1.0 DTD, return the named entity reference as is.
If the entity is a MediaWiki-specific alias, returns the HTML equivalent. Otherwise, returns HTML-escaped text of pseudo-entity source (eg &foo;)
| string | $name |
Definition at line 921 of file Sanitizer.php.
|
staticprivate |
Definition at line 862 of file Sanitizer.php.
|
staticprivate |
Remove '', and everything between.
To avoid leaving blank lines, when a comment is both preceded and followed by a newline (ignoring spaces), trim leading and trailing spaces and one of the newlines.
| string | $text |
Definition at line 526 of file Sanitizer.php.
|
staticprivate |
Cleans up HTML, removes dangerous tags and attributes, and removes HTML comments.
| string | $text | |
| callback | $processCallback | to do any variable or parameter replacements in HTML attribute values |
| array | $args | for the processing callback |
Definition at line 340 of file Sanitizer.php.
|
static |
Encode an attribute value for HTML tags, with extra armoring against further wiki processing.
| $text |
Definition at line 695 of file Sanitizer.php.
|
static |
Definition at line 1055 of file Sanitizer.php.
|
static |
Take a fragment of (potentially invalid) HTML and return a version with any tags removed, encoded as plain text.
Warning: this return value must be further escaped for literal inclusion in HTML output as of 1.10!
| string | $text | HTML fragment |
Definition at line 1201 of file Sanitizer.php.
|
staticprivate |
Returns true if a given Unicode codepoint is a valid character in XML.
| int | $codepoint |
Definition at line 955 of file Sanitizer.php.
|
static |
Take an array of attribute names and values and normalize or discard illegal values for the given element type.
| array | $attribs | |
| string | $element |
Check for legal values where the DTD limits things.
Check for unique id attribute :P
Definition at line 575 of file Sanitizer.php.
 1.8.1.2 (using Doxyfile)
1.8.1.2 (using Doxyfile)