|
ILIAS
Release_4_0_x_branch Revision 61816
|
|
ILIAS
Release_4_0_x_branch Revision 61816
|
Our in-house implementation of a parser. More...
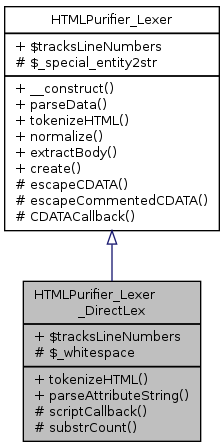
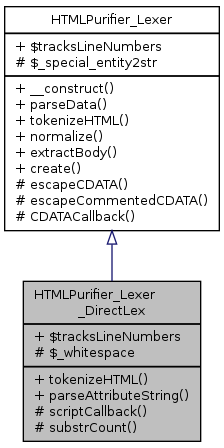
 Inheritance diagram for HTMLPurifier_Lexer_DirectLex: Collaboration diagram for HTMLPurifier_Lexer_DirectLex:
Inheritance diagram for HTMLPurifier_Lexer_DirectLex: Collaboration diagram for HTMLPurifier_Lexer_DirectLex:Public Member Functions | |
| tokenizeHTML ($html, $config, $context) | |
| Lexes an HTML string into tokens. | |
| parseAttributeString ($string, $config, $context) | |
| Takes the inside of an HTML tag and makes an assoc array of attributes. | |
| Public Member Functions inherited from HTMLPurifier_Lexer | |
| __construct () | |
| parseData ($string) | |
| Parses special entities into the proper characters. | |
| normalize ($html, $config, $context) | |
| Takes a piece of HTML and normalizes it by converting entities, fixing encoding, extracting bits, and other good stuff. | |
| extractBody ($html) | |
| Takes a string of HTML (fragment or document) and returns the content. | |
Data Fields | |
| $tracksLineNumbers = true | |
| Data Fields inherited from HTMLPurifier_Lexer | |
| $tracksLineNumbers = false | |
| Whether or not this lexer implements line-number/column-number tracking. | |
Protected Member Functions | |
| scriptCallback ($matches) | |
| Callback function for script CDATA fudge. | |
| substrCount ($haystack, $needle, $offset, $length) | |
| PHP 5.0.x compatible substr_count that implements offset and length. | |
Protected Attributes | |
| $_whitespace = "\x20\x09\x0D\x0A" | |
| Whitespace characters for str(c)spn. | |
| Protected Attributes inherited from HTMLPurifier_Lexer | |
| $_special_entity2str | |
| Most common entity to raw value conversion table for special entities. | |
Additional Inherited Members | |
| Static Public Member Functions inherited from HTMLPurifier_Lexer | |
| static | create ($config) |
| Retrieves or sets the default Lexer as a Prototype Factory. | |
| Static Protected Member Functions inherited from HTMLPurifier_Lexer | |
| static | escapeCDATA ($string) |
| Translates CDATA sections into regular sections (through escaping). | |
| static | escapeCommentedCDATA ($string) |
| Special CDATA case that is especially convoluted for <script> | |
| static | CDATACallback ($matches) |
| Callback function for escapeCDATA() that does the work. | |
Our in-house implementation of a parser.
A pure PHP parser, DirectLex has absolutely no dependencies, making it a reasonably good default for PHP4. Written with efficiency in mind, it can be four times faster than HTMLPurifier_Lexer_PEARSax3, although it pales in comparison to HTMLPurifier_Lexer_DOMLex.
Definition at line 13 of file DirectLex.php.
| HTMLPurifier_Lexer_DirectLex::parseAttributeString | ( | $string, | |
| $config, | |||
| $context | |||
| ) |
Takes the inside of an HTML tag and makes an assoc array of attributes.
| $string | Inside of tag excluding name. |
Definition at line 342 of file DirectLex.php.
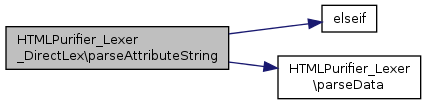
References $config, $key, $size, elseif(), and HTMLPurifier_Lexer\parseData().
Referenced by tokenizeHTML().
Here is the call graph for this function: Here is the caller graph for this function:
|
protected |
Callback function for script CDATA fudge.
| $matches,in | form of array(opening tag, contents, closing tag) |
Definition at line 27 of file DirectLex.php.
|
protected |
PHP 5.0.x compatible substr_count that implements offset and length.
Definition at line 323 of file DirectLex.php.
Referenced by tokenizeHTML().
Here is the caller graph for this function:| HTMLPurifier_Lexer_DirectLex::tokenizeHTML | ( | $string, | |
| $config, | |||
| $context | |||
| ) |
Lexes an HTML string into tokens.
| $string | String HTML. |
Reimplemented from HTMLPurifier_Lexer.
Definition at line 31 of file DirectLex.php.
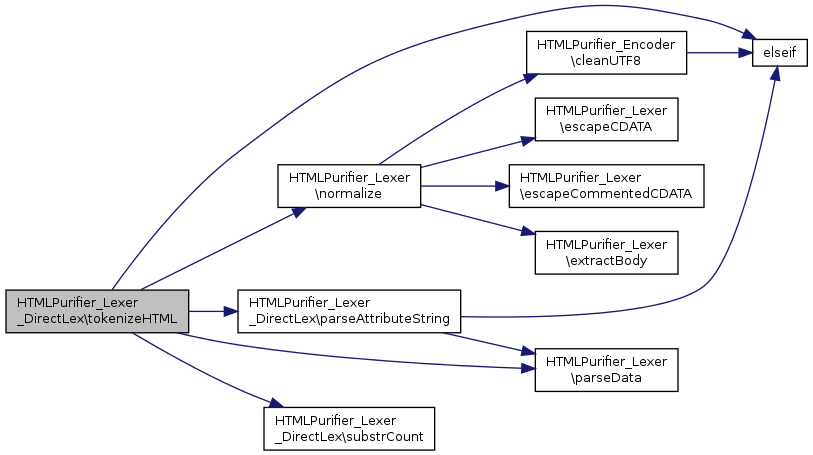
References $config, $type, elseif(), HTMLPurifier_Lexer\normalize(), parseAttributeString(), HTMLPurifier_Lexer\parseData(), and substrCount().
Here is the call graph for this function:
|
protected |
Whitespace characters for str(c)spn.
Definition at line 21 of file DirectLex.php.
| HTMLPurifier_Lexer_DirectLex::$tracksLineNumbers = true |
Definition at line 16 of file DirectLex.php.
 1.8.1.2 (using Doxyfile)
1.8.1.2 (using Doxyfile)