|
ILIAS
Release_4_2_x_branch Revision 61807
|
|
ILIAS
Release_4_2_x_branch Revision 61807
|
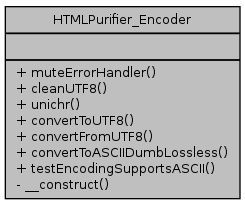
A UTF-8 specific character encoder that handles cleaning and transforming. More...
 Collaboration diagram for HTMLPurifier_Encoder:
Collaboration diagram for HTMLPurifier_Encoder:Static Public Member Functions | |
| static | muteErrorHandler () |
| Error-handler that mutes errors, alternative to shut-up operator. | |
| static | cleanUTF8 ($str, $force_php=false) |
| Cleans a UTF-8 string for well-formedness and SGML validity. | |
| static | unichr ($code) |
| Translates a Unicode codepoint into its corresponding UTF-8 character. | |
| static | convertToUTF8 ($str, $config, $context) |
| Converts a string to UTF-8 based on configuration. | |
| static | convertFromUTF8 ($str, $config, $context) |
| Converts a string from UTF-8 based on configuration. | |
| static | convertToASCIIDumbLossless ($str) |
| Lossless (character-wise) conversion of HTML to ASCII. | |
| static | testEncodingSupportsASCII ($encoding, $bypass=false) |
| This expensive function tests whether or not a given character encoding supports ASCII. | |
Private Member Functions | |
| __construct () | |
| Constructor throws fatal error if you attempt to instantiate class. | |
A UTF-8 specific character encoder that handles cleaning and transforming.
Definition at line 7 of file Encoder.php.
|
private |
Constructor throws fatal error if you attempt to instantiate class.
Definition at line 13 of file Encoder.php.
|
static |
Cleans a UTF-8 string for well-formedness and SGML validity.
It will parse according to UTF-8 and return a valid UTF8 string, with non-SGML codepoints excluded.
Definition at line 47 of file Encoder.php.
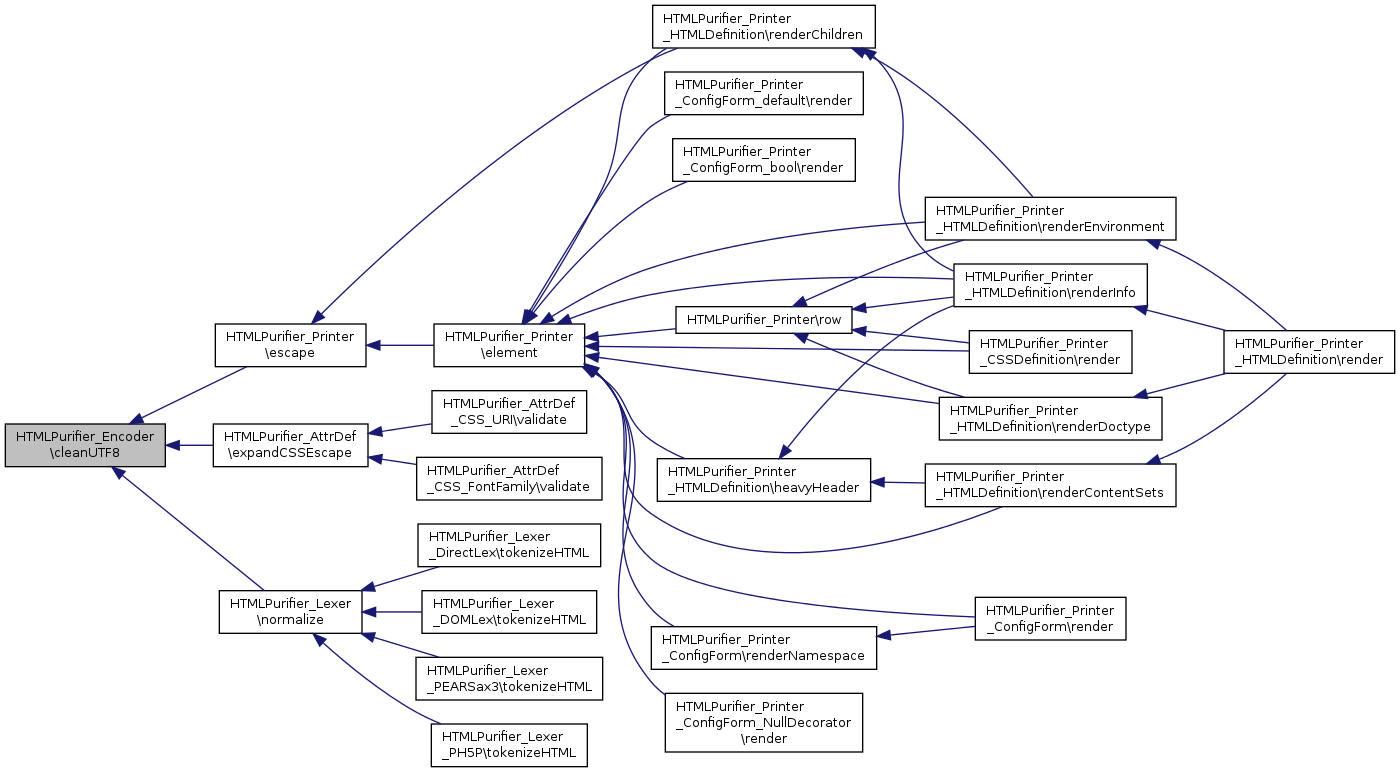
Referenced by HTMLPurifier_Printer\escape(), HTMLPurifier_AttrDef\expandCSSEscape(), and HTMLPurifier_Lexer\normalize().
Here is the caller graph for this function:
|
static |
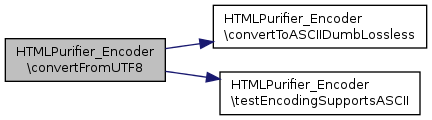
Converts a string from UTF-8 based on configuration.
Definition at line 299 of file Encoder.php.
References $config, convertToASCIIDumbLossless(), and testEncodingSupportsASCII().
Referenced by HTMLPurifier\purify().
Here is the call graph for this function: Here is the caller graph for this function:
|
static |
Lossless (character-wise) conversion of HTML to ASCII.
| $str | UTF-8 string to be converted to ASCII |
Definition at line 345 of file Encoder.php.
References $result.
Referenced by convertFromUTF8().
Here is the caller graph for this function:
|
static |
Converts a string to UTF-8 based on configuration.
Definition at line 266 of file Encoder.php.
References $config, and testEncodingSupportsASCII().
Referenced by HTMLPurifier\purify().
Here is the call graph for this function: Here is the caller graph for this function:
|
static |
Error-handler that mutes errors, alternative to shut-up operator.
Definition at line 20 of file Encoder.php.
|
static |
This expensive function tests whether or not a given character encoding supports ASCII.
7/8-bit encodings like Shift_JIS will fail this test, and require special processing. Variable width encodings shouldn't ever fail.
| string | $encoding | Encoding name to test, as per iconv format |
| bool | $bypass | Whether or not to bypass the precompiled arrays. |
Definition at line 387 of file Encoder.php.
References $ret.
Referenced by convertFromUTF8(), and convertToUTF8().
Here is the caller graph for this function:
|
static |
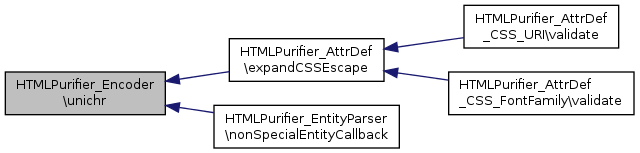
Translates a Unicode codepoint into its corresponding UTF-8 character.
Definition at line 226 of file Encoder.php.
References $ret.
Referenced by HTMLPurifier_AttrDef\expandCSSEscape(), and HTMLPurifier_EntityParser\nonSpecialEntityCallback().
Here is the caller graph for this function: 1.8.1.2 (using Doxyfile)
1.8.1.2 (using Doxyfile)