 Collaboration diagram for UtfNormal:
Collaboration diagram for UtfNormal:
Static Public Member Functions | |
| static | cleanUp ($string) |
| The ultimate convenience function! Clean up invalid UTF-8 sequences, and convert to normal form C, canonical composition. More... | |
| static | toNFC ($string) |
| Convert a UTF-8 string to normal form C, canonical composition. More... | |
| static | toNFD ($string) |
| Convert a UTF-8 string to normal form D, canonical decomposition. More... | |
| static | toNFKC ($string) |
| Convert a UTF-8 string to normal form KC, compatibility composition. More... | |
| static | toNFKD ($string) |
| Convert a UTF-8 string to normal form KD, compatibility decomposition. More... | |
| static | loadData () |
| Load the basic composition data if necessary. More... | |
| static | quickIsNFC ($string) |
| Returns true if the string is definitely in NFC. More... | |
| static | quickIsNFCVerify (&$string) |
| Returns true if the string is definitely in NFC. More... | |
| static | NFC ($string) |
| static | NFD ($string) |
| static | NFKC ($string) |
| static | NFKD ($string) |
| static | fastDecompose ($string, $map) |
| Perform decomposition of a UTF-8 string into either D or KD form (depending on which decomposition map is passed to us). More... | |
| static | fastCombiningSort ($string) |
| Sorts combining characters into canonical order. More... | |
| static | fastCompose ($string) |
| Produces canonically composed sequences, i.e. More... | |
| static | placebo ($string) |
| This is just used for the benchmark, comparing how long it takes to interate through a string without really doing anything of substance. More... | |
Detailed Description
Definition at line 112 of file UtfNormal.php.
Member Function Documentation
◆ cleanUp()
|
static |
The ultimate convenience function! Clean up invalid UTF-8 sequences, and convert to normal form C, canonical composition.
Fast return for pure ASCII strings; some lesser optimizations for strings containing only known-good characters. Not as fast as toNFC().
- Parameters
-
string $string a UTF-8 string
- Returns
- string a clean, shiny, normalized UTF-8 string
Definition at line 125 of file UtfNormal.php.
References NFC(), NORMALIZE_ICU, quickIsNFCVerify(), UNORM_NFC, UTF8_FFFE, UTF8_FFFF, and UTF8_REPLACEMENT.
Referenced by CleanUpTest\doTestBytes(), CleanUpTest\doTestDoubleBytes(), CleanUpTest\doTestTripleBytes(), CleanUpTest\testAscii(), CleanUpTest\testBomRegression(), CleanUpTest\testChunkRegression(), CleanUpTest\testForbiddenRegression(), CleanUpTest\testHangulRegression(), CleanUpTest\testInterposeRegression(), CleanUpTest\testLatin(), CleanUpTest\testLatinNormal(), CleanUpTest\testNull(), CleanUpTest\testOverlongRegression(), CleanUpTest\testSurrogateRegression(), and CleanUpTest\XtestAllChars().
Here is the call graph for this function: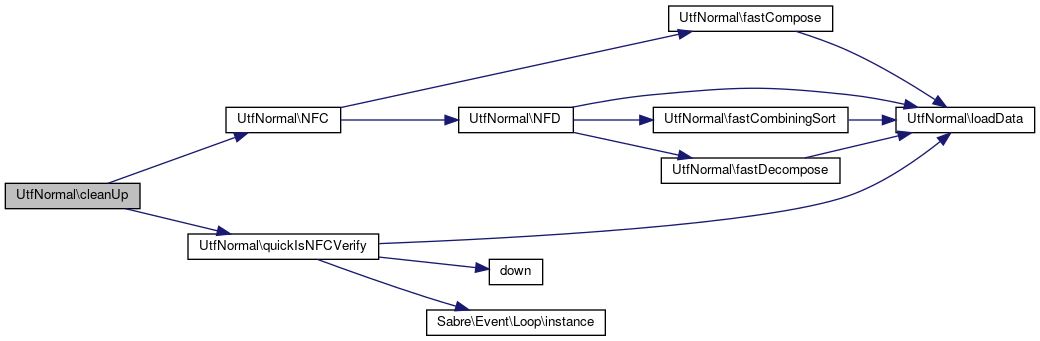 Here is the caller graph for this function:
Here is the caller graph for this function: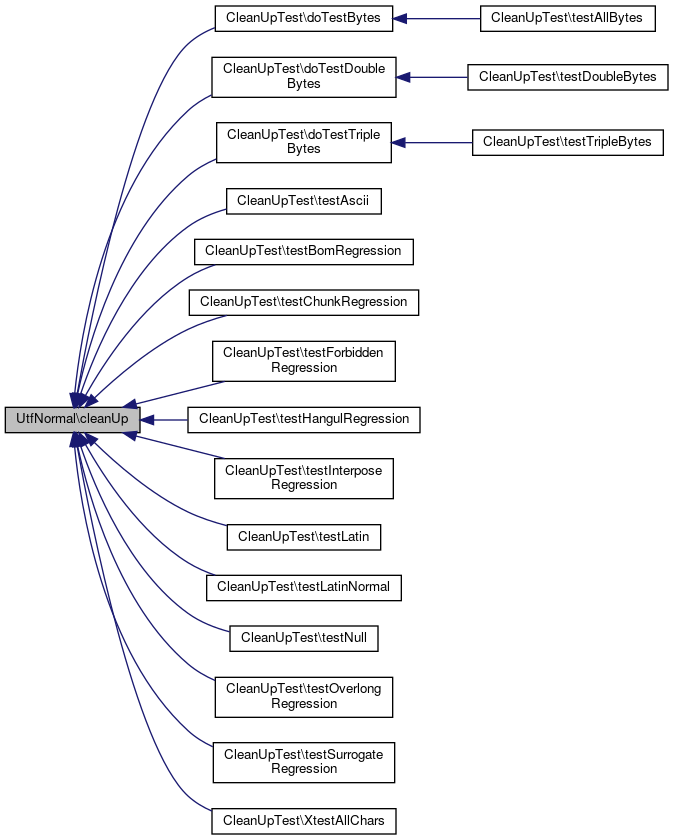
◆ fastCombiningSort()
|
static |
Sorts combining characters into canonical order.
This is the final step in creating decomposed normal forms D and KD.
- Parameters
-
string $string a valid, decomposed UTF-8 string. Input is not validated.
- Returns
- string a UTF-8 string with combining characters sorted in canonical order
Definition at line 638 of file UtfNormal.php.
References $c, $i, $n, $out, $utfCombiningClass, and loadData().
Referenced by NFD(), and NFKD().
Here is the call graph for this function: Here is the caller graph for this function:
Here is the caller graph for this function:
◆ fastCompose()
|
static |
Produces canonically composed sequences, i.e.
normal form C or KC.
- Parameters
-
string $string a valid UTF-8 string in sorted normal form D or KD. Input is not validated.
- Returns
- string a UTF-8 string with canonical precomposed characters used where possible
Definition at line 693 of file UtfNormal.php.
References $c, $i, $n, $out, $tail, $utfCanonicalComp, $utfCombiningClass, loadData(), UNICODE_HANGUL_FIRST, UNICODE_HANGUL_TCOUNT, UNICODE_HANGUL_VCOUNT, UTF8_HANGUL_FIRST, UTF8_HANGUL_LAST, UTF8_HANGUL_LBASE, UTF8_HANGUL_LEND, UTF8_HANGUL_TBASE, UTF8_HANGUL_TEND, UTF8_HANGUL_VBASE, and UTF8_HANGUL_VEND.
Referenced by NFC(), and NFKC().
Here is the call graph for this function: Here is the caller graph for this function:
Here is the caller graph for this function:
◆ fastDecompose()
|
static |
Perform decomposition of a UTF-8 string into either D or KD form (depending on which decomposition map is passed to us).
Input is assumed to be valid UTF-8. Invalid code will break.
- Parameters
-
string $string Valid UTF-8 string array $map hash of expanded decomposition map
- Returns
- string a UTF-8 string decomposed, not yet normalized (needs sorting)
Definition at line 576 of file UtfNormal.php.
References $c, $i, $index, $l, $map, $n, $out, $t, loadData(), UNICODE_HANGUL_FIRST, UNICODE_HANGUL_NCOUNT, UNICODE_HANGUL_TCOUNT, UTF8_HANGUL_FIRST, and UTF8_HANGUL_LAST.
Referenced by NFD(), and NFKD().
Here is the call graph for this function: Here is the caller graph for this function:
Here is the caller graph for this function: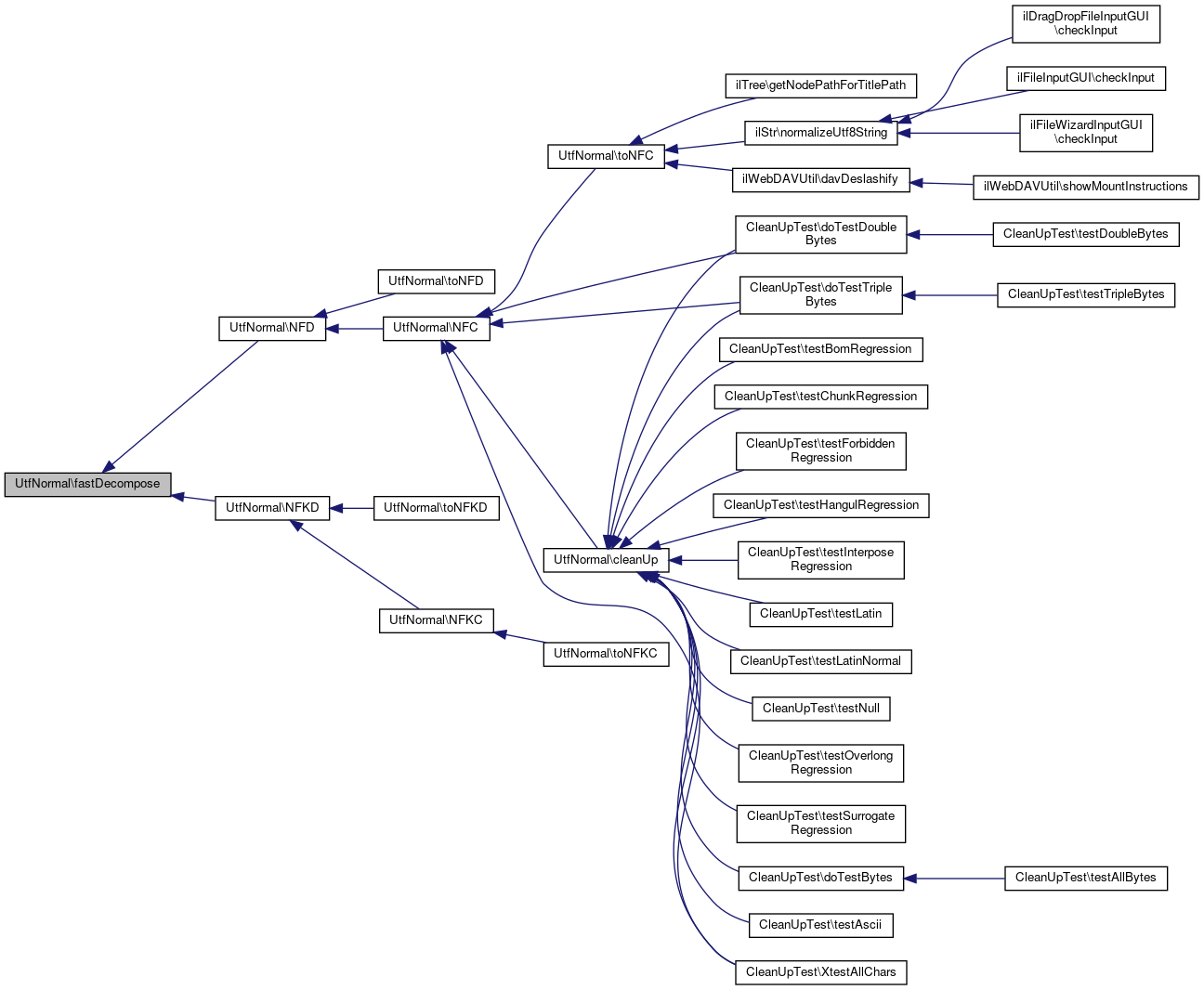
◆ loadData()
|
static |
Load the basic composition data if necessary.
Definition at line 232 of file UtfNormal.php.
References $utfCombiningClass.
Referenced by fastCombiningSort(), fastCompose(), fastDecompose(), NFD(), quickIsNFC(), and quickIsNFCVerify().
Here is the caller graph for this function: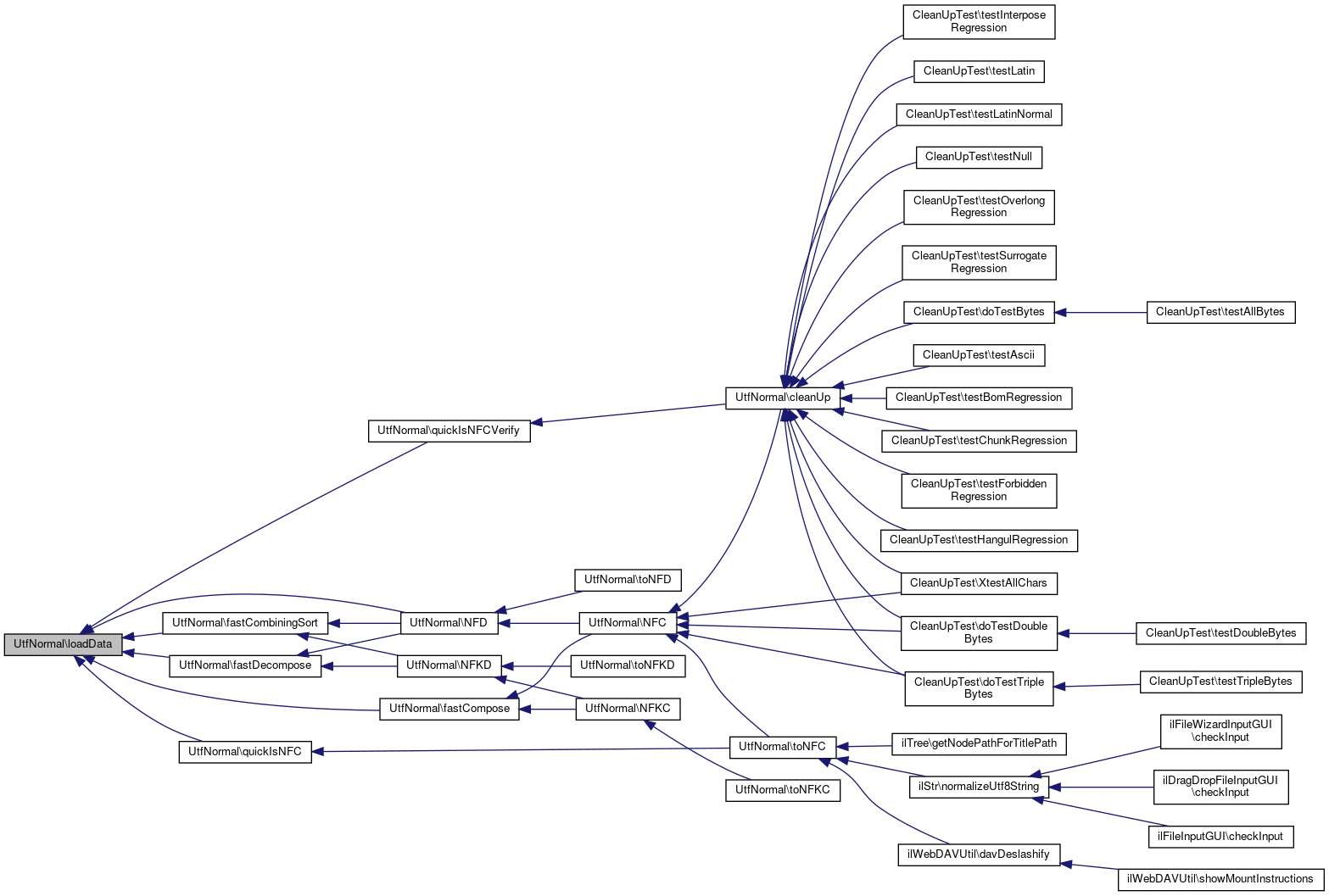
◆ NFC()
|
static |
- Parameters
-
string $string
- Returns
- string
Definition at line 517 of file UtfNormal.php.
References fastCompose(), and NFD().
Referenced by cleanUp(), CleanUpTest\doTestDoubleBytes(), CleanUpTest\doTestTripleBytes(), toNFC(), and CleanUpTest\XtestAllChars().
Here is the call graph for this function: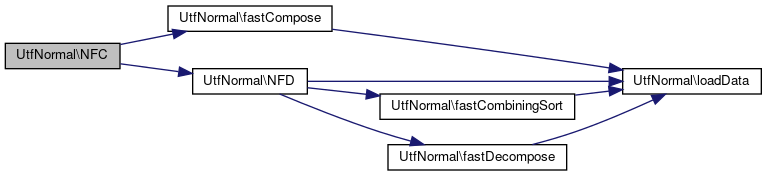 Here is the caller graph for this function:
Here is the caller graph for this function: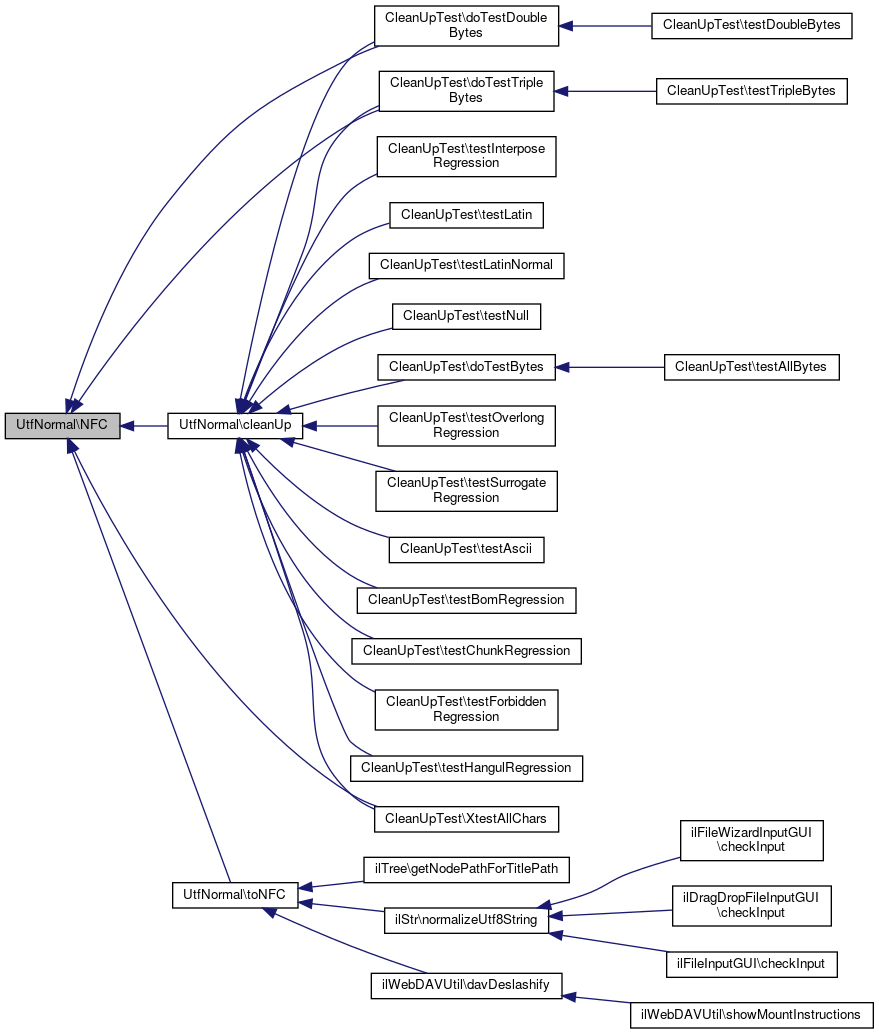
◆ NFD()
|
static |
- Parameters
-
string $string
- Returns
- string
Definition at line 528 of file UtfNormal.php.
References $utfCanonicalDecomp, fastCombiningSort(), fastDecompose(), and loadData().
Referenced by NFC(), and toNFD().
Here is the call graph for this function: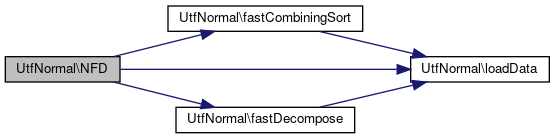 Here is the caller graph for this function:
Here is the caller graph for this function: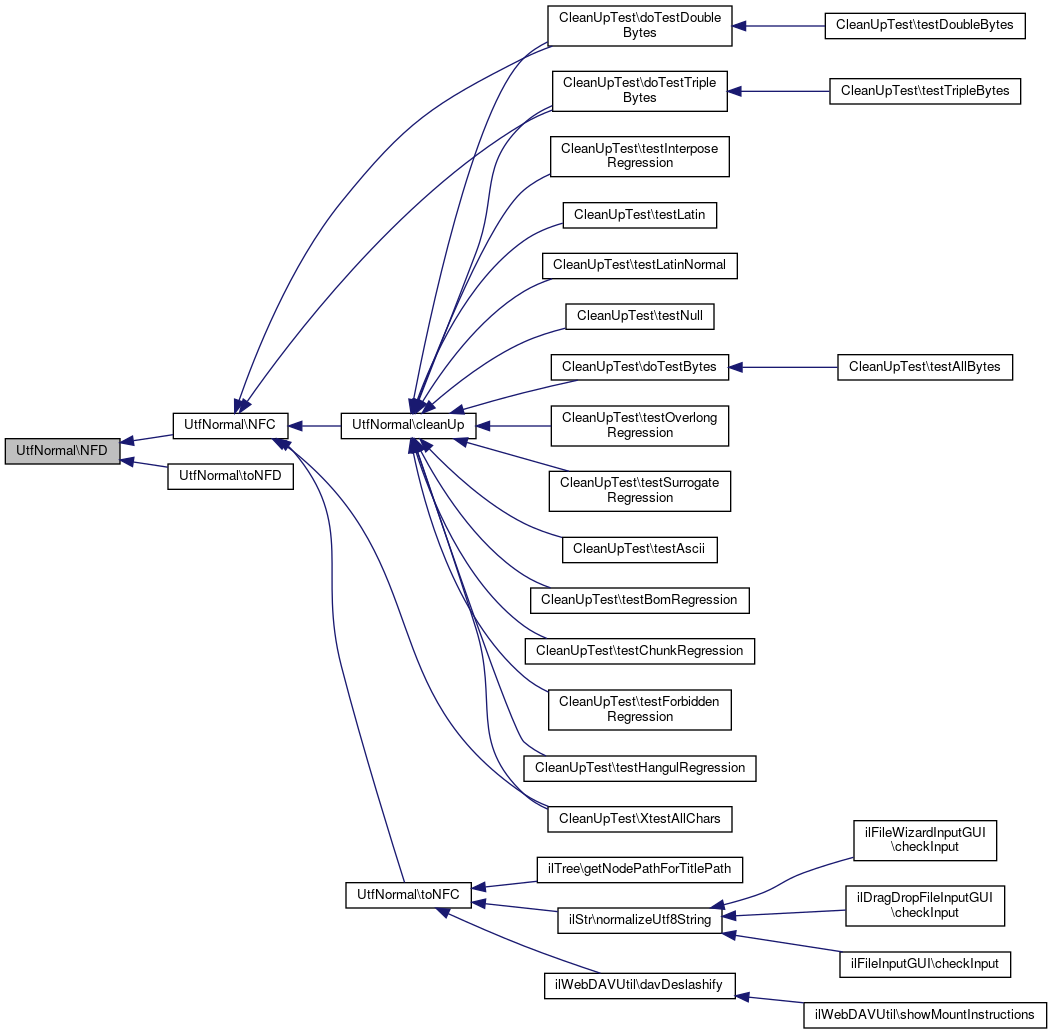
◆ NFKC()
|
static |
- Parameters
-
string $string
- Returns
- string
Definition at line 543 of file UtfNormal.php.
References fastCompose(), and NFKD().
Referenced by toNFKC().
Here is the call graph for this function: Here is the caller graph for this function:
Here is the caller graph for this function:
◆ NFKD()
|
static |
- Parameters
-
string $string
- Returns
- string
Definition at line 554 of file UtfNormal.php.
References $utfCompatibilityDecomp, fastCombiningSort(), and fastDecompose().
Referenced by NFKC(), and toNFKD().
Here is the call graph for this function: Here is the caller graph for this function:
Here is the caller graph for this function:
◆ placebo()
|
static |
This is just used for the benchmark, comparing how long it takes to interate through a string without really doing anything of substance.
- Parameters
-
string $string
- Returns
- string
Definition at line 829 of file UtfNormal.php.
◆ quickIsNFC()
|
static |
Returns true if the string is definitely in NFC.
Returns false if not or uncertain.
- Parameters
-
string $string a valid UTF-8 string. Input is not validated.
- Returns
- bool
Definition at line 247 of file UtfNormal.php.
References $c, $i, $n, $utfCombiningClass, and loadData().
Referenced by toNFC().
Here is the call graph for this function: Here is the caller graph for this function:
Here is the caller graph for this function: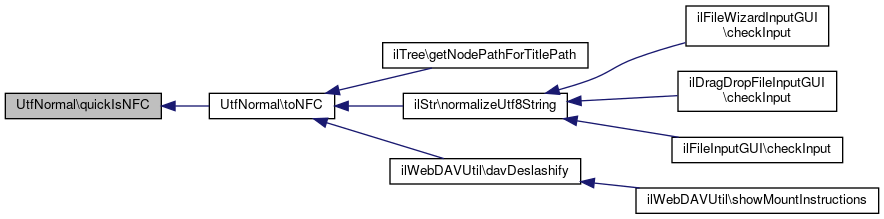
◆ quickIsNFCVerify()
|
static |
Returns true if the string is definitely in NFC.
Returns false if not or uncertain.
- Parameters
-
string $string a UTF-8 string, altered on output to be valid UTF-8 safe for XML.
Definition at line 291 of file UtfNormal.php.
References $base, $i, $n, $remaining, $utfCombiningClass, down(), Sabre\Event\Loop\instance(), loadData(), UTF8_FFFE, UTF8_FFFF, UTF8_MAX, UTF8_OVERLONG_A, UTF8_OVERLONG_B, UTF8_OVERLONG_C, UTF8_REPLACEMENT, and UTF8_SURROGATE_FIRST.
Referenced by cleanUp().
Here is the call graph for this function: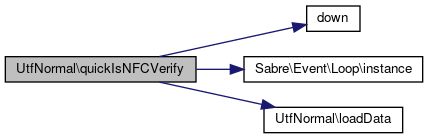 Here is the caller graph for this function:
Here is the caller graph for this function: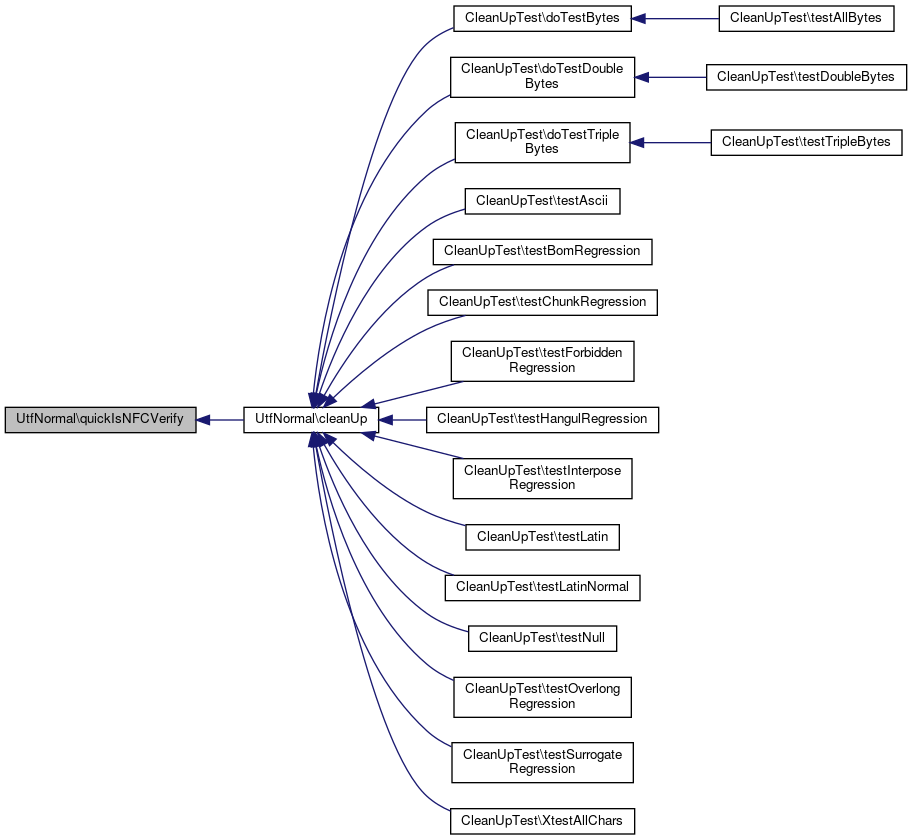
◆ toNFC()
|
static |
Convert a UTF-8 string to normal form C, canonical composition.
Fast return for pure ASCII strings; some lesser optimizations for strings containing only known-good characters.
- Parameters
-
string $string a valid UTF-8 string. Input is not validated.
- Returns
- string a UTF-8 string in normal form C
Definition at line 157 of file UtfNormal.php.
References NFC(), NORMALIZE_ICU, quickIsNFC(), and UNORM_NFC.
Referenced by ilWebDAVUtil\davDeslashify(), ilTree\getNodePathForTitlePath(), and ilStr\normalizeUtf8String().
Here is the call graph for this function: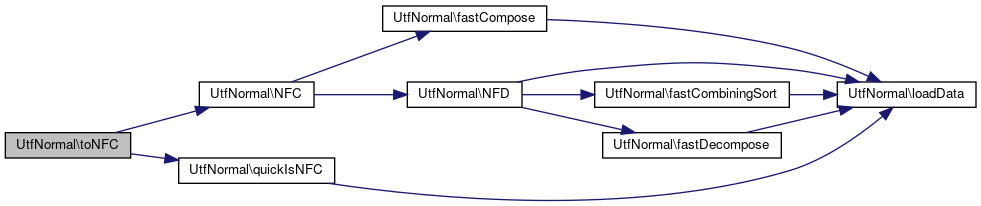 Here is the caller graph for this function:
Here is the caller graph for this function:
◆ toNFD()
|
static |
Convert a UTF-8 string to normal form D, canonical decomposition.
Fast return for pure ASCII strings.
- Parameters
-
string $string a valid UTF-8 string. Input is not validated.
- Returns
- string a UTF-8 string in normal form D
Definition at line 176 of file UtfNormal.php.
References NFD(), NORMALIZE_ICU, and UNORM_NFD.
Here is the call graph for this function:
◆ toNFKC()
|
static |
Convert a UTF-8 string to normal form KC, compatibility composition.
This may cause irreversible information loss, use judiciously. Fast return for pure ASCII strings.
- Parameters
-
string $string a valid UTF-8 string. Input is not validated.
- Returns
- string a UTF-8 string in normal form KC
Definition at line 196 of file UtfNormal.php.
References NFKC(), NORMALIZE_ICU, and UNORM_NFKC.
Here is the call graph for this function:
◆ toNFKD()
|
static |
Convert a UTF-8 string to normal form KD, compatibility decomposition.
This may cause irreversible information loss, use judiciously. Fast return for pure ASCII strings.
- Parameters
-
string $string a valid UTF-8 string. Input is not validated.
- Returns
- string a UTF-8 string in normal form KD
Definition at line 216 of file UtfNormal.php.
References NFKD(), NORMALIZE_ICU, and UNORM_NFKD.
Here is the call graph for this function:
The documentation for this class was generated from the following file:
- include/Unicode/UtfNormal.php
