A UTF-8 specific character encoder that handles cleaning and transforming. More...
 Collaboration diagram for HTMLPurifier_Encoder:
Collaboration diagram for HTMLPurifier_Encoder:
Static Public Member Functions | |
| static | muteErrorHandler () |
| Error-handler that mutes errors, alternative to shut-up operator. More... | |
| static | unsafeIconv ($in, $out, $text) |
| iconv wrapper which mutes errors, but doesn't work around bugs. More... | |
| static | iconv ($in, $out, $text, $max_chunk_size=8000) |
| iconv wrapper which mutes errors and works around bugs. More... | |
| static | cleanUTF8 ($str, $force_php=false) |
| Cleans a UTF-8 string for well-formedness and SGML validity. More... | |
| static | unichr ($code) |
| Translates a Unicode codepoint into its corresponding UTF-8 character. More... | |
| static | iconvAvailable () |
| static | convertToUTF8 ($str, $config, $context) |
| Convert a string to UTF-8 based on configuration. More... | |
| static | convertFromUTF8 ($str, $config, $context) |
| Converts a string from UTF-8 based on configuration. More... | |
| static | convertToASCIIDumbLossless ($str) |
| Lossless (character-wise) conversion of HTML to ASCII. More... | |
| static | testIconvTruncateBug () |
| glibc iconv has a known bug where it doesn't handle the magic //IGNORE stanza correctly. More... | |
| static | testEncodingSupportsASCII ($encoding, $bypass=false) |
| This expensive function tests whether or not a given character encoding supports ASCII. More... | |
Data Fields | |
| const | ICONV_OK = 0 |
| No bugs detected in iconv. More... | |
| const | ICONV_TRUNCATES = 1 |
| Iconv truncates output if converting from UTF-8 to another character set with //IGNORE, and a non-encodable character is found. More... | |
| const | ICONV_UNUSABLE = 2 |
| Iconv does not support //IGNORE, making it unusable for transcoding purposes. More... | |
Private Member Functions | |
| __construct () | |
| Constructor throws fatal error if you attempt to instantiate class. More... | |
Detailed Description
A UTF-8 specific character encoder that handles cleaning and transforming.
- Note
- All functions in this class should be static.
Definition at line 7 of file Encoder.php.
Constructor & Destructor Documentation
◆ __construct()
|
private |
Constructor throws fatal error if you attempt to instantiate class.
Definition at line 13 of file Encoder.php.
Member Function Documentation
◆ cleanUTF8()
|
static |
Cleans a UTF-8 string for well-formedness and SGML validity.
It will parse according to UTF-8 and return a valid UTF8 string, with non-SGML codepoints excluded.
Specifically, it will permit: \x{9}\x{A}\x{D}\x{20}-\x{7E}\x{A0}-\x{D7FF}\x{E000}-\x{FFFD}\x{10000}-\x{10FFFF} Source: https://www.w3.org/TR/REC-xml/#NT-Char Arguably this function should be modernized to the HTML5 set of allowed characters: https://www.w3.org/TR/html5/syntax.html#preprocessing-the-input-stream which simultaneously expand and restrict the set of allowed characters.
- Parameters
-
string $str The string to clean bool $force_php
- Returns
- string
- Note
- Just for reference, the non-SGML code points are 0 to 31 and 127 to 159, inclusive. However, we allow code points 9, 10 and 13, which are the tab, line feed and carriage return respectively. 128 and above the code points map to multibyte UTF-8 representations.
- Fallback code adapted from utf8ToUnicode by Henri Sivonen and hsivo.nosp@m.nen@.nosp@m.iki.f.nosp@m.i at http://iki.fi/hsivonen/php-utf8/ under the LGPL license. Notes on what changed are inside, but in general, the original code transformed UTF-8 text into an array of integer Unicode codepoints. Understandably, transforming that back to a string would be somewhat expensive, so the function was modded to directly operate on the string. However, this discourages code reuse, and the logic enumerated here would be useful for any function that needs to be able to understand UTF-8 characters. As of right now, only smart lossless character encoding converters would need that, and I'm probably not going to implement them.
Definition at line 134 of file Encoder.php.
Referenced by HTMLPurifier_Printer\escape(), HTMLPurifier_AttrDef\expandCSSEscape(), and HTMLPurifier_Lexer\normalize().
Here is the caller graph for this function: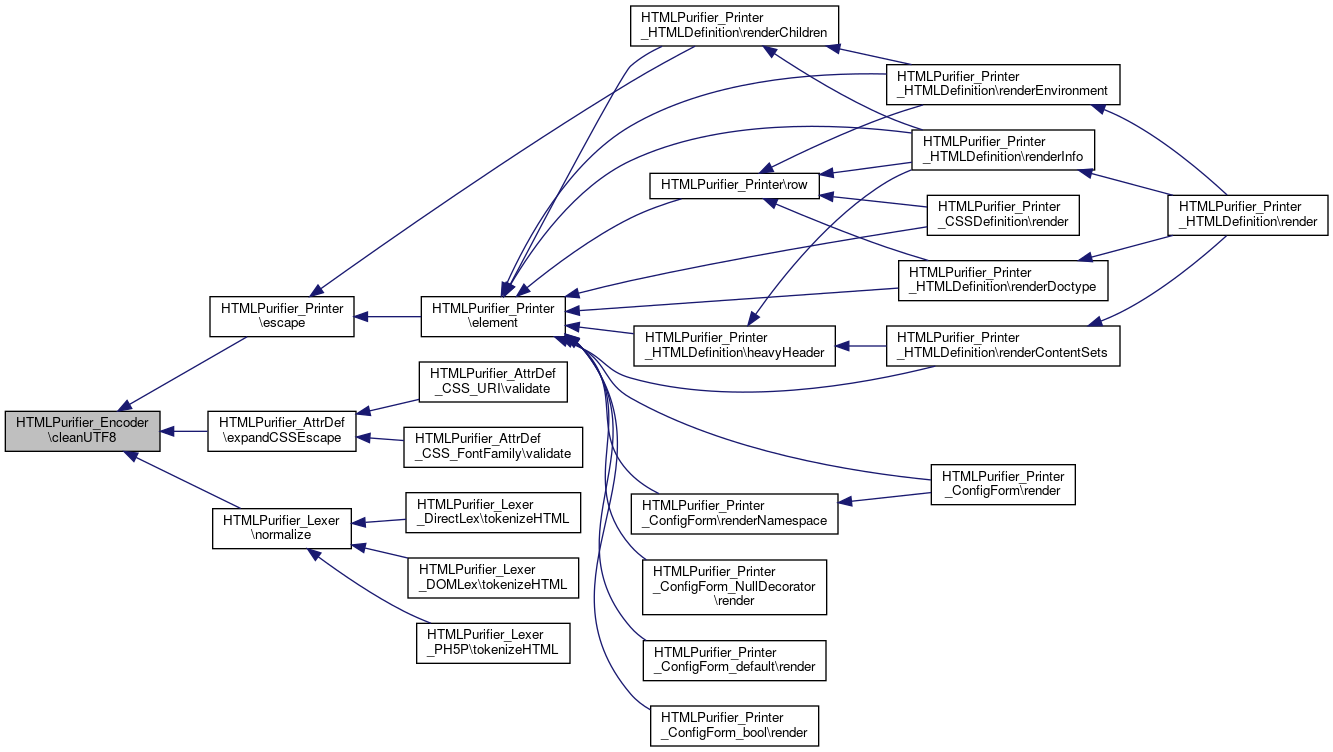
◆ convertFromUTF8()
|
static |
Converts a string from UTF-8 based on configuration.
- Parameters
-
string $str The string to convert HTMLPurifier_Config $config HTMLPurifier_Context $context
- Returns
- string
- Note
- Currently, this is a lossy conversion, with unexpressable characters being omitted.
Definition at line 426 of file Encoder.php.
References $config, convertToASCIIDumbLossless(), iconv(), iconvAvailable(), and testEncodingSupportsASCII().
Referenced by HTMLPurifier\purify().
Here is the call graph for this function: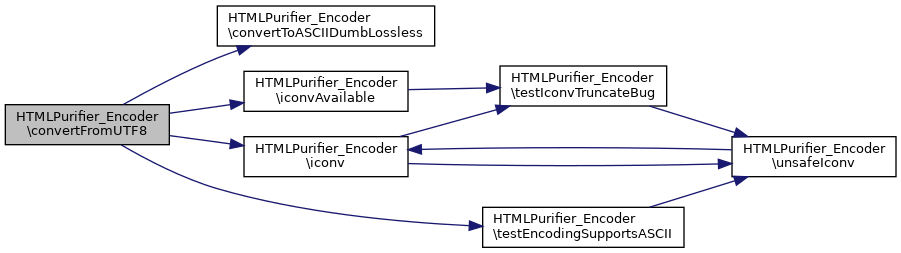 Here is the caller graph for this function:
Here is the caller graph for this function:
◆ convertToASCIIDumbLossless()
|
static |
Lossless (character-wise) conversion of HTML to ASCII.
- Parameters
-
string $str UTF-8 string to be converted to ASCII
- Returns
- string ASCII encoded string with non-ASCII character entity-ized
- Warning
- Adapted from MediaWiki, claiming fair use: this is a common algorithm. If you disagree with this license fudgery, implement it yourself.
- Note
- Uses decimal numeric entities since they are best supported.
- This is a DUMB function: it has no concept of keeping character entities that the projected character encoding can allow. We could possibly implement a smart version but that would require it to also know which Unicode codepoints the charset supported (not an easy task).
- Sort of with cleanUTF8() but it assumes that $str is well-formed UTF-8
Definition at line 480 of file Encoder.php.
Referenced by convertFromUTF8().
Here is the caller graph for this function:
◆ convertToUTF8()
|
static |
Convert a string to UTF-8 based on configuration.
- Parameters
-
string $str The string to convert HTMLPurifier_Config $config HTMLPurifier_Context $context
- Returns
- string
Definition at line 378 of file Encoder.php.
References $config, iconvAvailable(), testIconvTruncateBug(), and unsafeIconv().
Referenced by HTMLPurifier\purify().
Here is the call graph for this function: Here is the caller graph for this function:
Here is the caller graph for this function:
◆ iconv()
|
static |
iconv wrapper which mutes errors and works around bugs.
- Parameters
-
string $in Input encoding string $out Output encoding string $text The text to convert int $max_chunk_size
- Returns
- string
Definition at line 48 of file Encoder.php.
References $c, $code, $i, $in, $out, $r, $text, testIconvTruncateBug(), and unsafeIconv().
Referenced by convertFromUTF8(), and unsafeIconv().
Here is the call graph for this function: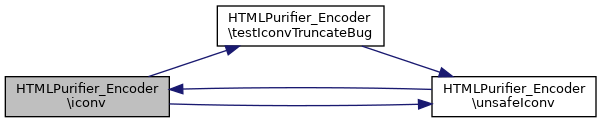 Here is the caller graph for this function:
Here is the caller graph for this function:
◆ iconvAvailable()
|
static |
- Returns
- bool
Definition at line 362 of file Encoder.php.
References ICONV_UNUSABLE, and testIconvTruncateBug().
Referenced by convertFromUTF8(), and convertToUTF8().
Here is the call graph for this function: Here is the caller graph for this function:
Here is the caller graph for this function:
◆ muteErrorHandler()
|
static |
Error-handler that mutes errors, alternative to shut-up operator.
Definition at line 21 of file Encoder.php.
◆ testEncodingSupportsASCII()
|
static |
This expensive function tests whether or not a given character encoding supports ASCII.
7/8-bit encodings like Shift_JIS will fail this test, and require special processing. Variable width encodings shouldn't ever fail.
- Parameters
-
string $encoding Encoding name to test, as per iconv format bool $bypass Whether or not to bypass the precompiled arrays.
- Returns
- Array of UTF-8 characters to their corresponding ASCII, which can be used to "undo" any overzealous iconv action.
Definition at line 571 of file Encoder.php.
References $c, $i, $r, $ret, and unsafeIconv().
Referenced by convertFromUTF8().
Here is the call graph for this function: Here is the caller graph for this function:
Here is the caller graph for this function:
◆ testIconvTruncateBug()
|
static |
glibc iconv has a known bug where it doesn't handle the magic //IGNORE stanza correctly.
In particular, rather than ignore characters, it will return an EILSEQ after consuming some number of characters, and expect you to restart iconv as if it were an E2BIG. Old versions of PHP did not respect the errno, and returned the fragment, so as a result you would see iconv mysteriously truncating output. We can work around this by manually chopping our input into segments of about 8000 characters, as long as PHP ignores the error code. If PHP starts paying attention to the error code, iconv becomes unusable.
- Returns
- int Error code indicating severity of bug.
Definition at line 537 of file Encoder.php.
References $c, $code, $r, ICONV_OK, ICONV_TRUNCATES, ICONV_UNUSABLE, and unsafeIconv().
Referenced by convertToUTF8(), iconv(), and iconvAvailable().
Here is the call graph for this function: Here is the caller graph for this function:
Here is the caller graph for this function:
◆ unichr()
|
static |
Translates a Unicode codepoint into its corresponding UTF-8 character.
- Note
- Based on Feyd's function at http://forums.devnetwork.net/viewtopic.php?p=191404#191404, which is in public domain.
- While we're going to do code point parsing anyway, a good optimization would be to refuse to translate code points that are non-SGML characters. However, this could lead to duplication.
- This is very similar to the unichr function in maintenance/generate-entity-file.php (although this is superior, due to its sanity checks).
Definition at line 315 of file Encoder.php.
References $code, $ret, $w, $x, and $y.
Referenced by HTMLPurifier_EntityParser\entityCallback(), HTMLPurifier_AttrDef\expandCSSEscape(), and HTMLPurifier_EntityParser\nonSpecialEntityCallback().
Here is the caller graph for this function:
◆ unsafeIconv()
|
static |
iconv wrapper which mutes errors, but doesn't work around bugs.
- Parameters
-
string $in Input encoding string $out Output encoding string $text The text to convert
- Returns
- string
Definition at line 32 of file Encoder.php.
References $in, $out, $r, $text, and iconv().
Referenced by convertToUTF8(), iconv(), testEncodingSupportsASCII(), and testIconvTruncateBug().
Here is the call graph for this function: Here is the caller graph for this function:
Here is the caller graph for this function:
Field Documentation
◆ ICONV_OK
| const HTMLPurifier_Encoder::ICONV_OK = 0 |
No bugs detected in iconv.
Definition at line 513 of file Encoder.php.
Referenced by testIconvTruncateBug().
◆ ICONV_TRUNCATES
| const HTMLPurifier_Encoder::ICONV_TRUNCATES = 1 |
Iconv truncates output if converting from UTF-8 to another character set with //IGNORE, and a non-encodable character is found.
Definition at line 517 of file Encoder.php.
Referenced by testIconvTruncateBug().
◆ ICONV_UNUSABLE
| const HTMLPurifier_Encoder::ICONV_UNUSABLE = 2 |
Iconv does not support //IGNORE, making it unusable for transcoding purposes.
Definition at line 521 of file Encoder.php.
Referenced by iconvAvailable(), and testIconvTruncateBug().
The documentation for this class was generated from the following file:
- libs/composer/vendor/ezyang/htmlpurifier/library/HTMLPurifier/Encoder.php
