|
ILIAS
eassessment Revision 61809
|
|
ILIAS
eassessment Revision 61809
|
Parser that uses PHP 5's DOM extension (part of the core). More...
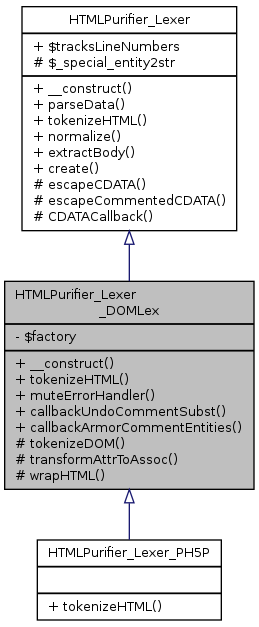
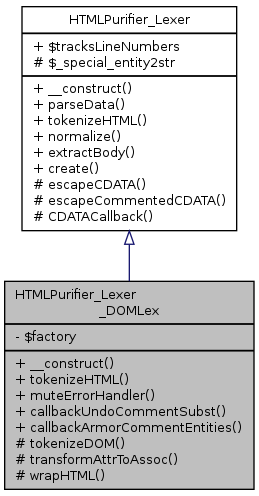
 Inheritance diagram for HTMLPurifier_Lexer_DOMLex: Collaboration diagram for HTMLPurifier_Lexer_DOMLex:
Inheritance diagram for HTMLPurifier_Lexer_DOMLex: Collaboration diagram for HTMLPurifier_Lexer_DOMLex:Public Member Functions | |
| __construct () | |
| tokenizeHTML ($html, $config, $context) | |
| Lexes an HTML string into tokens. | |
| muteErrorHandler ($errno, $errstr) | |
| An error handler that mutes all errors. | |
| callbackUndoCommentSubst ($matches) | |
| Callback function for undoing escaping of stray angled brackets in comments. | |
| callbackArmorCommentEntities ($matches) | |
| Callback function that entity-izes ampersands in comments so that callbackUndoCommentSubst doesn't clobber them. | |
| Public Member Functions inherited from HTMLPurifier_Lexer | |
| parseData ($string) | |
| Parses special entities into the proper characters. | |
| normalize ($html, $config, $context) | |
| Takes a piece of HTML and normalizes it by converting entities, fixing encoding, extracting bits, and other good stuff. | |
| extractBody ($html) | |
| Takes a string of HTML (fragment or document) and returns the content. | |
Protected Member Functions | |
| tokenizeDOM ($node, &$tokens, $collect=false) | |
| Recursive function that tokenizes a node, putting it into an accumulator. | |
| transformAttrToAssoc ($node_map) | |
| Converts a DOMNamedNodeMap of DOMAttr objects into an assoc array. | |
| wrapHTML ($html, $config, $context) | |
| Wraps an HTML fragment in the necessary HTML. | |
Private Attributes | |
| $factory | |
Additional Inherited Members | |
| Static Public Member Functions inherited from HTMLPurifier_Lexer | |
| static | create ($config) |
| Retrieves or sets the default Lexer as a Prototype Factory. | |
| Data Fields inherited from HTMLPurifier_Lexer | |
| $tracksLineNumbers = false | |
| Whether or not this lexer implements line-number/column-number tracking. | |
| Static Protected Member Functions inherited from HTMLPurifier_Lexer | |
| static | escapeCDATA ($string) |
| Translates CDATA sections into regular sections (through escaping). | |
| static | escapeCommentedCDATA ($string) |
| Special CDATA case that is especially convoluted for <script> | |
| static | CDATACallback ($matches) |
| Callback function for escapeCDATA() that does the work. | |
| Protected Attributes inherited from HTMLPurifier_Lexer | |
| $_special_entity2str | |
| Most common entity to raw value conversion table for special entities. | |
Parser that uses PHP 5's DOM extension (part of the core).
In PHP 5, the DOM XML extension was revamped into DOM and added to the core. It gives us a forgiving HTML parser, which we use to transform the HTML into a DOM, and then into the tokens. It is blazingly fast (for large documents, it performs twenty times faster than HTMLPurifier_Lexer_DirectLex,and is the default choice for PHP 5.
Definition at line 27 of file DOMLex.php.
| HTMLPurifier_Lexer_DOMLex::__construct | ( | ) |
Reimplemented from HTMLPurifier_Lexer.
Definition at line 32 of file DOMLex.php.
| HTMLPurifier_Lexer_DOMLex::callbackArmorCommentEntities | ( | $matches | ) |
Callback function that entity-izes ampersands in comments so that callbackUndoCommentSubst doesn't clobber them.
Definition at line 186 of file DOMLex.php.
| HTMLPurifier_Lexer_DOMLex::callbackUndoCommentSubst | ( | $matches | ) |
Callback function for undoing escaping of stray angled brackets in comments.
Definition at line 178 of file DOMLex.php.
| HTMLPurifier_Lexer_DOMLex::muteErrorHandler | ( | $errno, | |
| $errstr | |||
| ) |
|
protected |
Recursive function that tokenizes a node, putting it into an accumulator.
| $node | DOMNode to be tokenized. |
| $tokens | Array-list of already tokenized tokens. |
| $collect | Says whether or start and close are collected, set to false at first recursion because it's the implicit DIV tag you're dealing with. |
Definition at line 84 of file DOMLex.php.
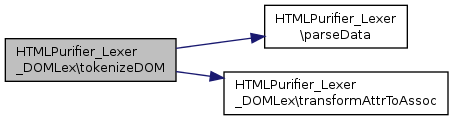
References $data, HTMLPurifier_Lexer\parseData(), and transformAttrToAssoc().
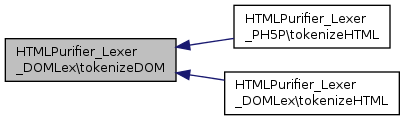
Referenced by HTMLPurifier_Lexer_PH5P\tokenizeHTML(), and tokenizeHTML().
Here is the call graph for this function: Here is the caller graph for this function:| HTMLPurifier_Lexer_DOMLex::tokenizeHTML | ( | $string, | |
| $config, | |||
| $context | |||
| ) |
Lexes an HTML string into tokens.
| $string | String HTML. |
Reimplemented from HTMLPurifier_Lexer.
Reimplemented in HTMLPurifier_Lexer_PH5P.
Definition at line 38 of file DOMLex.php.
References $comment, $config, HTMLPurifier_Lexer\normalize(), tokenizeDOM(), and wrapHTML().
Here is the call graph for this function:
|
protected |
Converts a DOMNamedNodeMap of DOMAttr objects into an assoc array.
| $attribute_list | DOMNamedNodeMap of DOMAttr objects. |
Definition at line 157 of file DOMLex.php.
Referenced by tokenizeDOM().
Here is the caller graph for this function:
|
protected |
Wraps an HTML fragment in the necessary HTML.
Definition at line 193 of file DOMLex.php.
Referenced by HTMLPurifier_Lexer_PH5P\tokenizeHTML(), and tokenizeHTML().
Here is the caller graph for this function:
|
private |
Definition at line 30 of file DOMLex.php.
 1.8.1.2 (using Doxyfile)
1.8.1.2 (using Doxyfile)